Cómo utilizar machine learning para asignar características sociodemográficas a una muestra de usuarios

Los datos de telefonía móvil se han convertido en una herramienta fundamental para la extracción de patrones de movilidad de la población. Sin embargo, estos datos pueden no contar con las características sociodemográficas de los usuarios. En este artículo mostraremos cómo en Nommon nos enfrentamos a estos problemas mediante el uso de técnicas de machine learning.
Los datos de telefonía móvil se han convertido en una herramienta fundamental para la extracción de patrones de movilidad de la población. Sin embargo, estos datos pueden carecer de información muy relevante para la construcción de estos patrones, como las características sociodemográficas de los usuarios, o puede que la información disponible no sea siempre fiable. Por ejemplo, muchos clientes no proporcionan información sobre su edad o género, mientras que a otros se les asignan valores incorrectos porque el usuario del teléfono no es el mismo que el titular del contrato. Entonces, ¿cómo podemos superar estas limitaciones?
En este artículo mostraremos cómo en Nommon nos enfrentamos a estos problemas mediante el uso de técnicas de machine learning (ML). Explicaremos un enfoque novedoso para la estimación de la edad y el género del usuario utilizando como variables predictivas los patrones de movilidad sugeridos en la literatura y observados en los registros de telefonía móvil. El procedimiento se puede dividir en tres pasos principales que detallaremos a lo largo de nuestro artículo. Estos son:
- Identificar las diferencias en los patrones de movilidad de personas de diferentes grupos de edad y género señaladas en la literatura. Los indicadores de movilidad con diferencias más significativas serán seleccionados y enriquecidos con nuevos patrones obtenidos directamente de los datos de telefonía móvil.
- Seleccionar una muestra fiable de usuarios de telefonía móvil cuyos valores de edad y género sabemos que son correctos. Esta será la muestra de entrenamiento al construir nuestros modelos predictivos.
- Desarrollar modelos de machine learning capaces de estimar la edad y el género de los usuarios de telefonía móvil que carecen de valores correctos. En el caso del modelo de edad, los usuarios se clasificarán en cuatro grupos: 0-18, 19-44, 45-64 y> 65. Las variables de entrada de los modelos serán las seleccionadas en el primer paso.
Primer paso: revisión de la literatura
Existen una serie de indicadores de movilidad que, de acuerdo con la literatura sobre transporte, presentan variaciones importantes entre los diferentes grupos de edad y género: el número promedio de viajes, el propósito del viaje, la distancia del viaje, la duración del viaje, la distribución temporal de los viajes y el radio de giro (movimiento promedio que realiza una persona con respecto a su centro de masa, es decir, el “tamaño” de su trayectoria a lo largo del día).
Para decidir cuáles son los patrones más relevantes para nuestro estudio, comenzamos con un análisis de las encuestas de hogares más recientes disponibles en Madrid (2018), Valencia (2019) y Sevilla (2017). Para cada indicador de movilidad mencionado en la literatura, se estudió su distribución entre los diferentes grupos de edad y género en cada encuesta. La siguiente figura muestra la distribución de la distancia media de viaje por día en la encuesta de Madrid. Se puede observar que el indicador alcanza un pico en los grupos de población activa (mayoritariamente de 30 a 60 años), siendo estos segmentos los que presentan mayores diferencias entre hombres y mujeres. El pico puede explicarse por el hecho de que las personas de los grupos activos tienen que desplazarse todos los días, mientras que las personas de fuera de esos grupos llevan una vida más sedentaria (personas mayores) o van a la escuela cerca de su casa (jóvenes), mientras que la diferencia entre los hombres y las mujeres de esos grupos pueden explicarse por el hecho de que las mujeres realizan viajes más cortos desde el hogar, mientras que los hombres suelen viajar distancias más largas y realizar otras actividades de ocio después del trabajo.
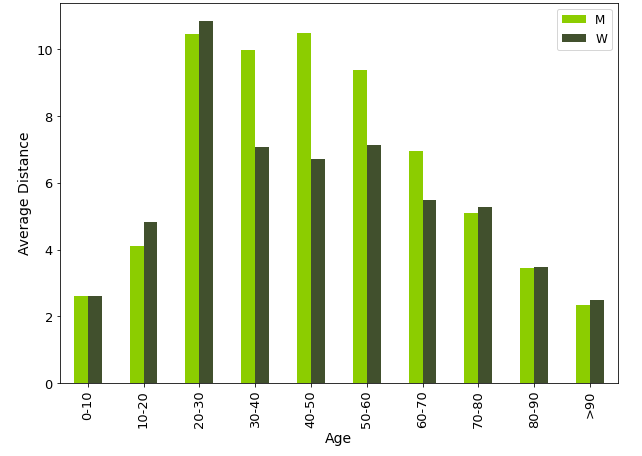
Después de realizar el análisis de la encuesta, las variables seleccionadas como más significativas para la predicción de la edad y el género fueron: el número promedio de viajes, la distancia promedio del viaje y el radio de giro. Una vez que se eligieron esas variables, se utilizó la longitudinalidad inherente de los datos de telefonía móvil para agregar nuevos campos que podrían ayudar a capturar otros patrones:
- Se agregaron dos indicadores: el promedio de viajes hacia o desde el trabajo y la distancia entre el hogar y el trabajo, para poder distinguir con mayor claridad los grupos de población activa del resto.
- Las variables referentes al número de viajes y distancia media se segmentaron en corta y larga distancia con el fin de captar mejor el comportamiento de las personas trabajadoras que viajan largas distancias en tren o avión. Ambas variables también se dividieron en días laborables y fines de semana para caracterizar mejor a los jóvenes y ancianos, que tienden a desplazarse con mayor frecuencia los fines de semana.
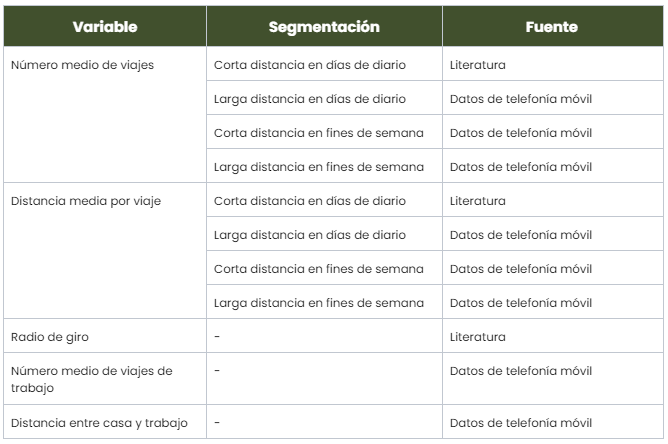
Después de unir las variables longitudinales de la telefonía móvil con las de la encuesta, obtenemos las once variables finales seleccionadas para nuestro modelo de machine learning:
Segundo paso: conseguir la muestra de entrenamiento
Ya tenemos las variables del modelo, pero ¿cómo podemos entrenar un modelo que las use? En primer lugar, necesitamos una muestra de los datos de telefonía móvil que sea utilizada en el proceso de entrenamiento de nuestro modelo. En machine learning, seleccionar una muestra de entrenamiento que sea lo suficientemente representativa como para que el modelo desarrollado sea capaz de generalizar correctamente es clave para el desarrollo de un modelo eficiente. Por tanto, debemos obtener una muestra de usuarios que cubra todos los posibles grupos de edad y género y, sobre todo, necesitamos que su edad y género sean fiables.
Como se mencionó anteriormente, algunos de los usuarios de telefonía móvil tienen asignados valores incorrectos de edad y género (por ejemplo, si el usuario final no es el mismo que el titular de la línea del teléfono), o directamente no tienen ningún valor asignado. Por lo tanto, para conseguir nuestra muestra fiable, solo se seleccionaron aquellos usuarios que eran miembros únicos de su contrato y que sí contaban con información de edad y género. Sin embargo, esta muestra presenta dos inconvenientes: primero, no hay usuarios menores de 18 años (todos los clientes que son titulares únicos de su contrato son mayores de edad) y, en segundo lugar, para los adultos, la muestra está desequilibrada en términos de edad, ya que el 50 % de los usuarios están en el segmento de entre 19 a 44 años, el 35 % tienen entre 45 y 64 años y solo el 15 % tienen más de 65 años. Para superar estos problemas, se siguieron los siguientes pasos:
- Para hacer frente a la falta de muestra de menores de 18 años, se siguió un enfoque anidado. En primer lugar, se entrenó un modelo de ML utilizando los patrones de movilidad de la encuesta de hogares de Madrid para clasificar a los usuarios en dos grupos: menores y adultos. A continuación, se entrenó un modelo utilizando la muestra fiable obtenida de los datos de telefonía móvil para clasificar a los adultos en grupos de edad más pequeños (19-44, 45-64 y >65).
- Para tratar el desequilibrio de la muestra en adultos, se utilizó una técnica de oversampling llamada SMOTE [1], que básicamente aumenta artificialmente los grupos más pequeños creando nuevas muestras sintéticas que no son exactamente duplicadas de las existentes, sino una combinación de las mismas.
Tercer paso: crear nuestros modelos de machine learning
Una vez que se obtiene la muestra fiable, se calculan los indicadores de movilidad seleccionados en el primer paso. Y ahora ya estamos listos para entrenar a los modelos. El planteamiento para construir los modelos predictivos fue el siguiente:
- Construcción del modelo de edad:
- Crear un modelo de machine learning entrenado solo con datos de encuestas que pueda predecir si un usuario tiene más o menos de 18 años.
- Construir un modelo de machine learning sobre la muestra fiable de usuarios capaz de estimar si su edad está en el grupo 19-44, 45-64 o >65.
- Construcción del modelo de género: entrenar un modelo de machine learning capaz de estimar el género.
El modelo de edad
Comencemos con el modelo de edad basado en los datos de la encuesta. Para poder entrenar un modelo con datos de encuestas y luego evaluarlo en los usuarios procedentes de los datos de telefonía móvil, las variables de entrada del modelo deben poder calcularse a partir de ambos conjuntos de datos. Por ello, la cantidad de variables que podemos calcular es menor que las mencionadas en el apartado anterior, ya que de la encuesta no se puede extraer información longitudinal, como viajes de larga distancia y datos de fines de semana. Las variables finales utilizadas para calibrar el modelo fueron el número promedio de viajes de corta distancia en días laborables, la distancia promedio, el radio de giro, el número de viajes asociados al trabajo y la distancia entre el hogar y el trabajo.
El proceso para entrenar este modelo fue el siguiente:
- Primero, el conjunto de datos se divide (estratifica) en un conjunto de entrenamiento y uno de test. Además, se aplicó un proceso de estandarización al conjunto de entrenamiento diferenciando por distrito de origen de los usuarios, para poder de esta forma mantener todas las variables en el mismo rango, ya que los indicadores de movilidad son diferentes según la región en la que viven. Esta estandarización se aplicó después directamente sobre el conjunto de test.
- El siguiente paso consiste en realizar un proceso de selección de modelos. Durante este proceso, se utilizaron cuatro técnicas de machine learning con diferentes combinaciones de sus parámetros para calibrar un modelo sobre la muestra de entrenamiento que clasifica a cada participante de la encuesta como adulto o menor de edad. Las técnicas probadas fueron árboles de decisión (DT), Random Forest (RF), máquinas de soporte vectorial y redes neuronales (perceptrón multicapa). Para obtener el mejor modelo para cada una de estas técnicas, se utilizó el método de remuestreo conocido como validación cruzada (CV) de k pliegues [2].
- El error de validación promedio obtenido en la validación cruzada se calculó utilizando la métrica F1-Score, que calcula el promedio armónico entre la precisión y el recall. La definición de cada una de estas métricas es la siguiente:
- Precisión: número de usuarios correctamente clasificados como pertenecientes a una clase con respecto al número total de usuarios clasificados como pertenecientes a esa clase.
- Recall: número de usuarios correctamente clasificados como pertenecientes a una clase con respecto al número total de usuarios que realmente pertenecen a esa clase.
- F1-Score: promedio armónico de precisión y recall. Como puede haber modelos con, por ejemplo, alto recall y baja precisión, es interesante dar un número único que tenga en cuenta ambas métricas. El uso de la media armónica evita obstaculizar el bajo rendimiento de una de las dos métricas (por ejemplo, evita que el modelo obtenga una puntuación de 0,5 cuando la precisión es 1 y el recall 0).
- Después de calcular el error de validación promedio para cada técnica y cada combinación de parámetros, se seleccionó el mejor modelo.
La validación cruzada y los resultados de las pruebas para el mejor modelo identificado, el árbol de decisión, se muestran en la siguiente tabla:
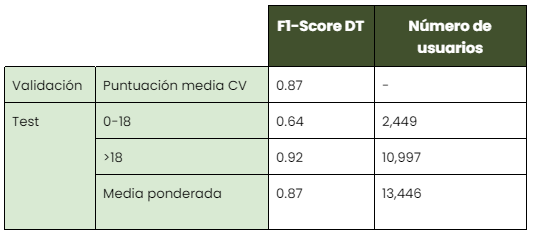
¡Parece que el modelo puede estimar casi perfectamente a los usuarios adultos! En cuanto a las personas menores de edad, la puntuación es de casi dos tercios, lo que también es adecuado para nuestros propósitos.
Una vez que se entrena el modelo de encuesta, es el momento de calibrar el modelo de edad basado en datos de telefonía móvil. Este modelo clasifica a los adultos en uno de los siguientes grupos: 19-44, 45-64 o >65. El procedimiento de entrenamiento es similar al del modelo de edad basado en encuestas con la única diferencia de que este se entrena aplicando el oversampling sobre los datos de entrenamiento desbalanceados gracias al algoritmo SMOTE explicado anteriormente.
Las técnicas probadas en este caso fueron Random Forest, Gradient Boosting, el perceptrón multicapa y el método de los k-vecinos más cercanos (KNN). El modelo con mejores resultados de validación cruzada fue Random Forest. Los resultados finales de este modelo se muestran en la siguiente tabla:
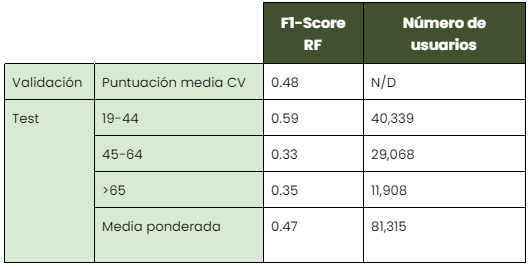
El rendimiento es inferior al obtenido en el modelo de encuesta, ya que algunos grupos son más difíciles de predecir (45-64, >65). La mejor puntuación de validación obtenida es 0,48 (15 puntos más que el modelo de referencia, que arrojaría 0,33). Esto parece indicar que utilizando únicamente los indicadores de movilidad seleccionados no se puede segmentar perfectamente a los usuarios en función de su edad.
El modelo de género
En cuanto al género, se siguió el mismo enfoque, pero sin tener que solucionar el problema del balanceo, ya que en la muestra fiable se dispone casi del mismo número de hombres (51 %) que de mujeres (49 %).
El F1-Score obtenido en este caso fue de 0.55, lo que implica que el género es más difícil de estimar usando patrones de movilidad, ya que hombres y mujeres no son tan diferentes en este aspecto. Sin embargo, en estos casos, no se debe dejar de buscar mejoras. Puede haber otras variables que estimen mejor el género de los usuarios de telefonía móvil. Algunos ejemplos pueden ser datos de navegación, o información de mensajería o llamada.
Conclusión
En este artículo hemos visto cómo podemos asignar atributos sociodemográficos con un alto grado de fiabilidad a un conjunto de usuarios de telefonía móvil que carecen de esa información. Hemos explicado cómo se puede paliar esta falta de información desarrollando modelos predictivos a través de técnicas de machine learning, resumiendo los análisis exploratorios y de preprocesamiento que se requieren antes de poder calibrar los modelos.
El desarrollo de estos modelos, que aprovechan el enorme potencial de los datos de telefonía móvil a la hora de capturar los patrones de movilidad de la población, nos permitirá realizar estudios de movilidad a múltiples niveles. Por ejemplo, podremos examinar las diferencias de movilidad entre mujeres y hombres de diferentes edades y en cualquier región o ciudad de España.
Finalmente, hemos visto que aún hay margen de mejora, especialmente en la predicción del género de los usuarios, por lo que seguiremos realizando un análisis más profundo de la extensa información que brindan los datos de telefonía móvil para obtener nuevos patrones que puedan diferenciar mejor a mujeres y hombres, así como personas de diferentes grupos de edad.
Bibliografía
[1] Chawla N. et al (2002), “SMOTE: Synthetic Minority Over-sampling Technique“, Journal of Artificial Intelligence Research, 16 (1), 321-357, https://doi.org/10.1613/jair.953
[2] Berrar D. (2018), “Cross-Validation”, Reference Module in Life Sciences, https://doi.org/10.1016/B978-0-12-809633-8.20349-X.

